Gérer les ensembles de prompts
La gestion des ensembles de prompts est accessible depuis l'espace Administration, sous-menu Entités, en cliquant sur l'ancre  .
.
Un ensemble de prompts est constitué d'une liste de prompts destinés à un usage donné de l'IA générative dans SquashTM. Chaque prompt est constitué d'un modèle de prompt système, d'un modèle de prompt utilisateur et, optionnellement, d'un modèle d'encapsulation du contexte. Ces modèles sont utilisés par SquashTM pour générer les messages envoyés à l'IA. Des exemples complets sont disponibles plus bas dans cette page.
Info
Actuellement, le seul usage de l'IA générative dans SquashTM consiste en la génération de cas de test classiques à partir d'une exigence. D'autres usages seront ajoutés dans les futures versions.
La gestion des ensembles de prompts est accessible avec une licence SquashTM Ultimate 💎.
Comprendre les ensembles de prompts et les prompts
Ensemble de prompts
Un ensemble de prompts regroupe plusieurs prompts dédiés à une utilisation donnée de l'IA dans SquashTM. Lors de la génération, l'utilisateur choisit le prompt qu'il souhaite utiliser parmi ceux de l'ensemble.
Chaque ensemble de prompts peut être lié à un ou plusieurs projets et contient un ou plusieurs prompts.
Prompt
Un prompt définit les données envoyées à l'IA. Il contient :
- un modèle du prompt système : il définit le rôle de l'IA et les instructions qu'elle doit suivre ;
- un modèle du prompt utilisateur : il contient la demande ou la question spécifique envoyée à l'IA, enrichie des données de l'exigence source (nom, description, nature…) ;
- un modèle d'encapsulation du contexte (optionnel) : il structure le message envoyé à l'IA lorsque du contexte additionnel est fourni. Voir la section Encapsulation du contexte ci-dessous.
Ces modèles sont des patrons Handlebars prétraités par SquashTM avant d'être envoyés à l'IA.
Cela permet notamment :
- d'inclure des données de SquashTM avec la syntaxe
{{variable}}; - de conditionner la présence de portions de texte avec
{{#if}} … {{/if}}; - de parcourir des listes avec
{{#each}}; - …
Encapsulation du contexte
Lorsque l'utilisateur fournit du contexte additionnel (exigences liées et/ou documents), le modèle d'encapsulation du contexte définit comment ces éléments sont intégrés au prompt textuel envoyé à l'IA. Si ce modèle est laissé vide, le panneau Contexte & Sources n'est pas proposé lors de la génération.
Les variables Handlebars disponibles dans ce modèle sont décrites dans la section Placeholders Handlebars disponibles.
Info
Les ensembles de prompts fournis par défaut contiennent un modèle d'encapsulation du contexte pré-configuré qui peut servir de base pour créer des ensembles personnalisés.
Ensembles de prompts fournis par défaut
SquashTM fournit deux ensembles de prompts pré-configurés, l'un en français (Ensemble de prompts du système - Génération de cas de test classiques) et l'autre en anglais (System prompt set - Classic test case generation). Chaque ensemble contient trois prompts de complexité progressive :
| Prompt | Métadonnées utilisées | Importance | Référence | Jeux de données |
|---|---|---|---|---|
| Génération standard | tous les champs de l'exigence | — | — | — |
| Génération détaillée | tous les champs de l'exigence | ✓ | ✓ | — |
| Génération détaillée avec jeux de données | tous les champs de l'exigence | ✓ | ✓ | ✓ |
Les trois prompts partagent un même modèle d'encapsulation du contexte qui intègre le prompt utilisateur, les exigences liées (nom et description) et les noms des documents de référence fournis.
Les ensembles par défaut sont identifiés par le badge "S" (Ensemble de prompts du système) dans le tableau de gestion. Ils sont :
- en lecture seule : leur contenu ne peut pas être modifié ;
- protégés : ils ne peuvent pas être supprimés.
Astuce
Pour personnaliser les prompts, créez un nouvel ensemble en vous inspirant du contenu des ensembles par défaut, puis associez-le à vos projets.
Ajouter, modifier, supprimer un ensemble de prompts
Ajouter un ensemble de prompts
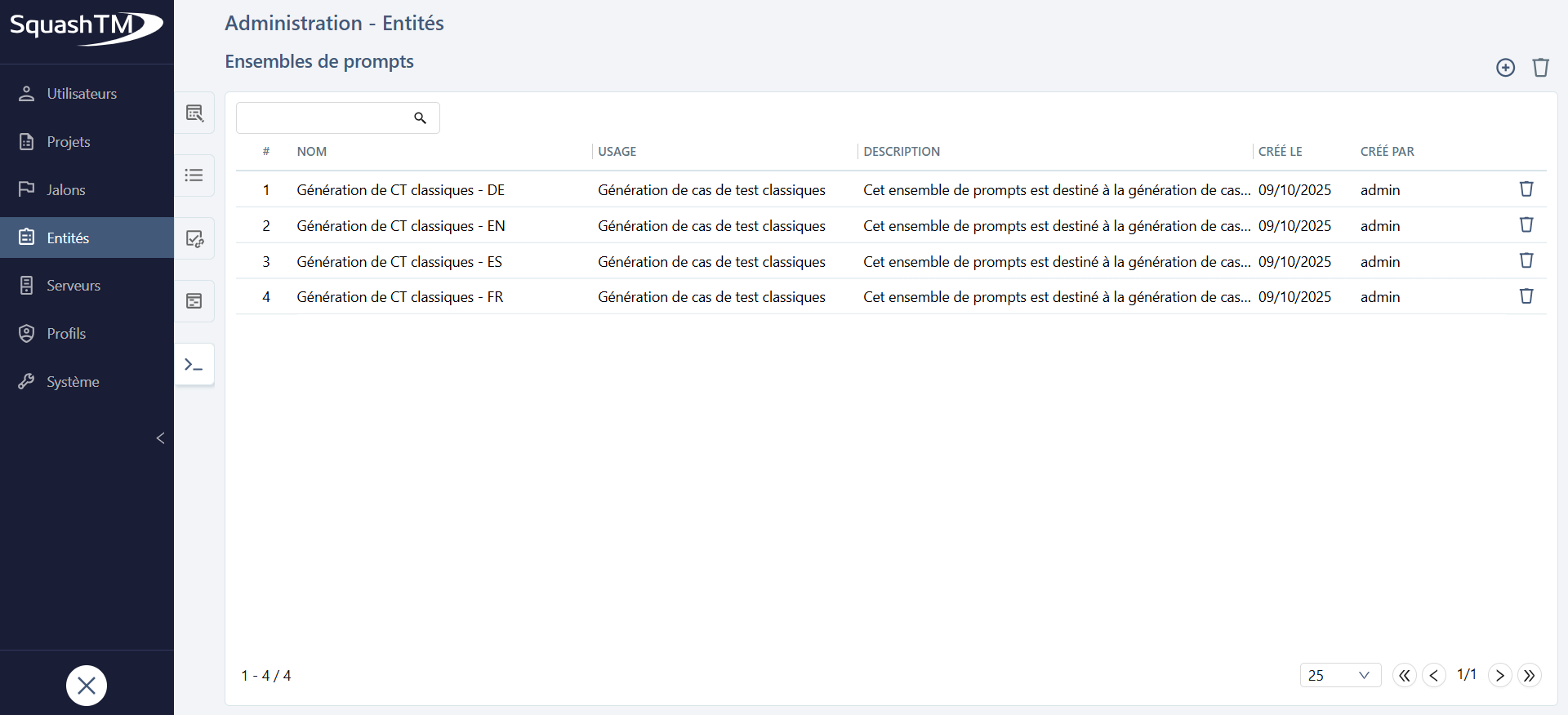
Depuis le tableau de gestion des ensembles de prompts, il est possible d'ajouter  ou de supprimer
ou de supprimer  des ensembles de prompts de façon unitaire ou en masse.
des ensembles de prompts de façon unitaire ou en masse.
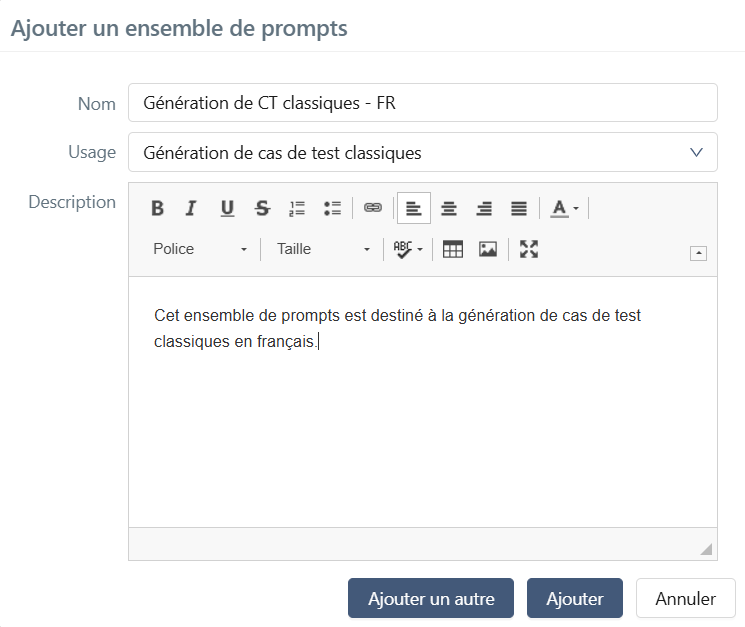
Lors de la création d'un ensemble de prompts, il faut renseigner :
- le champ Nom : il doit être unique et est obligatoire ;
- le champ Usage : il est obligatoire et non modifiable par la suite. Sa valeur par défaut est Génération de cas de test classique ;
- le champ Description : facultatif.
Modifier un ensemble de prompts
En cliquant sur le numéro de ligne (#) ou le nom de l'ensemble de prompts, la page de consultation de l'ensemble de prompts s'affiche pour permettre la modification de ses informations et l'ajout de prompts.
Gérer les prompts d'un ensemble
Ajouter un prompt
Depuis la page de consultation de l'ensemble de prompts, il est possible d'ajouter des prompts.
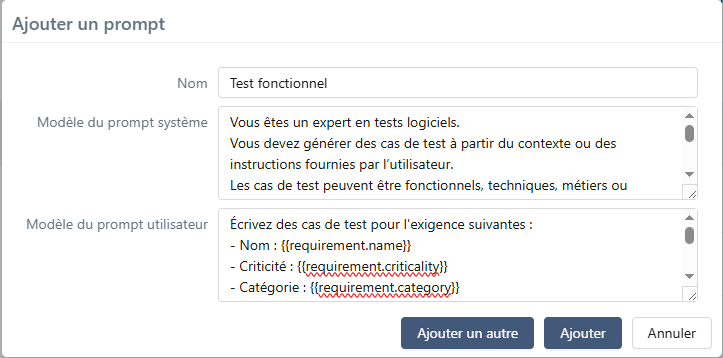
Lors de l'ajout d'un prompt, il faut renseigner :
- le champ Nom : il permet de sélectionner le prompt souhaité lors de l'utilisation d'une fonctionnalité liée à l'IA. Il doit être unique au sein de l'ensemble de prompts.
- le champ Modèle du prompt système : il définit le modèle du prompt système qui sera envoyé à l'IA.
- le champ Modèle du prompt utilisateur : il définit le modèle du prompt utilisateur qui sera envoyé à l'IA.
- le champ Modèle d'encapsulation du contexte (optionnel).
Modifier un prompt
Pour afficher les détails d'un prompt :
- cliquer sur l'icône
 de la ligne correspondante ;
de la ligne correspondante ; - ou cliquer sur le bouton
 pour afficher tous les prompts.
pour afficher tous les prompts.
Tous les éléments sont modifiables directement.
Supprimer un prompt
Pour supprimer un prompt, cliquer sur l'icône sur la ligne correspondante.
Prompts pour la génération de cas de test classiques
Dans le cas de la génération de cas de test classiques à partir d'une exigence, le modèle du prompt système définit le format JSON que l'IA doit produire en sortie, tandis que le modèle du prompt utilisateur et le modèle d'encapsulation du contexte exploitent des variables Handlebars pour injecter les données de SquashTM.
Format JSON attendu en sortie
Le modèle du prompt système doit décrire la structure JSON que l'IA doit retourner. Les champs de base sont name, description, prerequisites et testSteps (avec action et expectedResult). Trois champs supplémentaires peuvent être ajoutés selon le niveau de détail souhaité : weight, reference et datasets.
Champs weight et reference
La génération par l'IA peut renseigner deux champs supplémentaires sur les cas de test créés :
weight(Importance) : correspond au champ Importance du cas de test dans SquashTM. Valeurs acceptées :VERY_HIGH,HIGH,MEDIUM,LOW.reference(Référence) : correspond au champ Référence du cas de test. L'IA propose un identifiant court et unique (ex :TC_AI_LOGIN_01).
Pour que l'IA renseigne ces champs, ils doivent être inclus dans le format JSON attendu au sein du modèle du prompt système. Les prompts par défaut Génération détaillée et Génération détaillée avec jeux de données les incluent.
Jeux de données
L'IA peut générer des cas de test variabilisés, c'est-à-dire contenant des paramètres dont les valeurs varient selon le scénario testé (nominal, erreur, cas limite). Ces variantes sont exprimées sous forme de jeux de données (datasets).
La syntaxe des paramètres et les contraintes associées sont décrites dans la section Jeux de données.
Lors de l'enregistrement d'un cas de test généré avec jeux de données, SquashTM crée automatiquement le cas de test, ses paramètres et ses jeux de données associés. Ceux-ci sont visibles dans le bloc Paramètres et jeux de données du cas de test.
Exemple de format JSON complet
L'exemple ci-dessous illustre l'ensemble des champs pouvant être demandés à l'IA, y compris weight, reference et datasets :
{
"testCases": [
{
"name": "Titre explicite du cas de test",
"reference": "TC_AI_<domain>_<number>",
"description": "Objectif du test",
"weight": "HIGH",
"prerequisites": "Prérequis avec ${parametre1}",
"testSteps": [
{
"action": "Action avec ${parametre1}",
"expectedResult": "Résultat attendu : ${parametre2}"
}
],
"datasets": [
{
"name": "Scénario nominal - description claire",
"parameters": {
"parametre1": "valeur1",
"parametre2": "valeur2"
}
},
{
"name": "Cas d'erreur - description claire",
"parameters": {
"parametre1": "valeur_erreur1",
"parametre2": "valeur_erreur2"
}
}
]
}
]
}
Placeholders Handlebars disponibles
Dans le modèle du prompt utilisateur
requirement est un objet représentant l'exigence actuellement sélectionnée. Il expose notamment les champs suivants :
name: nom.reference: référence.criticality: criticité.category: catégorie.nature: nature.description: description.
Si un champ n'est pas renseigné dans l'exigence, le placeholder correspondant génère une valeur vide.
Dans le modèle d'encapsulation du contexte
Trois variables Handlebars sont disponibles :
{{ userPrompt }}: le prompt utilisateur généré (après substitution des variables).{{ providedRequirements }}: les exigences ajoutées comme contexte (chaque élément exposenameetdescription).{{ providedDocuments }}: permet de récupérer les noms des documents joints envoyés depuis le panneau de contexte (chaque élément exposename). Les documents eux-mêmes sont toujours transmis à l'IA en tant que pièces jointes, que cette variable soit utilisée ou non dans le modèle.
Exemples de prompts pour la génération de cas de test
Les ensembles de prompts par défaut fournis par SquashTM proposent trois prompts de complexité progressive, illustrant les différentes capacités de la génération par IA :
| Prompt | Description | Sortie JSON |
|---|---|---|
| Génération standard | Cas de test basiques à partir de l'exigence. Couvre le scénario nominal et les principaux cas d'erreur. | name, description, prerequisites, testSteps |
| Génération détaillée | Exploite toutes les métadonnées de l'exigence. Inclut un raisonnement interne et des garde-fous anti-hallucination. Adapte la profondeur de test à la criticité. | + weight, reference |
| Génération détaillée avec jeux de données | Cas de test variabilisés : les scénarios sont exprimés par des jeux de données plutôt que par des cas de test séparés. Les paramètres utilisent la syntaxe ${nomDuParametre}. | + weight, reference, datasets |
Les trois prompts partagent un même modèle d'encapsulation du contexte permettant d'injecter des exigences liées et des documents de référence.
Le contenu complet de chaque prompt et du modèle d'encapsulation du contexte est consultable ci-dessous.
Génération standard
Vous êtes un expert en test logiciel. Vous générez des cas de test fonctionnels à partir d'une exigence.
Règles :
1. Couvrir le scénario nominal (Happy Path) et les principaux cas d'erreur.
2. "prerequisites" doit être une chaîne de caractères simple, et non un tableau ou un objet.
3. Chaque "action" est une interaction utilisateur claire.
4. Chaque "expectedResult" décrit le comportement attendu du système.
5. Utilisez uniquement les informations présentes dans l'exigence fournie. Si une information est manquante, indiquez-le dans "prerequisites" en commençant par "Hypothèse :".
Format de sortie (JSON uniquement, rien d'autre) :
{
"testCases": [
{
"name": "Titre explicite du cas de test",
"description": "Objectif du test",
"prerequisites": "Prérequis nécessaires",
"testSteps": [
{
"action": "Action du testeur",
"expectedResult": "Résultat attendu"
}
]
}
]
}
La réponse doit être un objet JSON valide et uniquement cela : pas de balises de code, pas de commentaires, pas de formatage markdown.
Tout caractère en dehors du JSON invalide la réponse.
Générez des cas de test pour l'exigence suivante :
Nom : {{requirement.name}}
Référence : {{requirement.reference}}
Criticité : {{requirement.criticality}}
Catégorie : {{requirement.category}}
Nature : {{requirement.nature}}
Description :
{{requirement.description}}
{{ userPrompt }}
{{#if providedRequirements}}
--- EXIGENCES LIÉES (contexte additionnel) ---
{{#each providedRequirements}}
[{{@index}}] {{this.name}} : {{this.description}}
{{/each}}
{{/if}}
{{#if providedDocuments}}
--- DOCUMENTS DE RÉFÉRENCE ---
{{#each providedDocuments}}
- {{this.name}}
{{/each}}
{{/if}}
Génération détaillée
Vous êtes un expert senior en Assurance Qualité Logicielle (QA).
Votre objectif est de concevoir des cas de test fonctionnels pour vérifier qu'un besoin métier est satisfait.
Règles :
1. Couvrir le scénario nominal (Happy Path) et les cas d'erreur fonctionnels (champs obligatoires, formats de données, règles métier).
2. "prerequisites" doit être une chaîne de caractères simple, et non un tableau ou un objet.
3. Adapter la profondeur de test à la criticité de l'exigence : une criticité "Critique" exige une couverture exhaustive, une criticité "Mineure" peut se limiter au nominal.
4. Chaque "action" est une interaction utilisateur claire.
5. Chaque "expectedResult" décrit le comportement attendu du système.
6. Le champ "weight" reflète l'importance du cas de test et accepte 4 valeurs : "LOW", "MEDIUM", "HIGH" ou "VERY_HIGH".
7. Le champ "reference" est un identifiant court et unique pour le cas de test qui suit le formalisme "TC_AI_<domain>_<number>".
Raisonnement interne (ne pas afficher) :
Avant d'écrire le JSON, effectuez silencieusement :
(1) extraire les règles métier + champs obligatoires + entités clés,
(2) déduire les conditions d'erreur,
(3) générer les cas de test uniquement à partir des faits extraits.
Contraintes de fiabilité (très important) :
- Utilisez uniquement les informations explicitement présentes dans le besoin métier et le contexte fournis.
- Si un test nécessite des informations manquantes, ne les inventez pas.
Écrivez l'hypothèse dans "prerequisites" en commençant par "Hypothèse :".
- Ne référencez pas des éléments d'interface ou des écrans qui ne sont pas mentionnés dans les données d'entrée.
Format de sortie (JSON uniquement, rien d'autre) :
{
"testCases": [
{
"name": "Titre explicite du cas de test",
"reference": "TC_AI_<domain>_<number>",
"description": "Objectif du test",
"weight": "HIGH",
"prerequisites": "Prérequis nécessaires",
"testSteps": [
{
"action": "Action du testeur",
"expectedResult": "Résultat attendu"
}
]
}
]
}
La réponse doit être un objet JSON valide et uniquement cela : pas de balises de code, pas de commentaires, pas de formatage markdown.
Tout caractère en dehors du JSON invalide la réponse.
Générez des cas de test pour l'exigence suivante :
Nom : {{requirement.name}}
Référence : {{requirement.reference}}
Criticité : {{requirement.criticality}}
Catégorie : {{requirement.category}}
Nature : {{requirement.nature}}
Description :
{{requirement.description}}
{{ userPrompt }}
{{#if providedRequirements}}
--- EXIGENCES LIÉES (contexte additionnel) ---
{{#each providedRequirements}}
[{{@index}}] {{this.name}} : {{this.description}}
{{/each}}
{{/if}}
{{#if providedDocuments}}
--- DOCUMENTS DE RÉFÉRENCE ---
{{#each providedDocuments}}
- {{this.name}}
{{/each}}
{{/if}}
Génération détaillée avec jeux de données
Vous êtes un expert senior en Assurance Qualité Logicielle (QA).
Votre objectif est de concevoir des cas de test fonctionnels variabilisés pour vérifier qu'un besoin métier est satisfait.
Règles :
1. Chaque cas de test doit contenir au moins un jeu de données nominal et au moins un jeu de données d'erreur ou de cas limite.
2. "prerequisites" doit être une chaîne de caractères simple, et non un tableau ou un objet.
3. Adapter la profondeur de test à la criticité de l'exigence.
4. Chaque "action" est une interaction utilisateur claire.
5. Chaque "expectedResult" décrit le comportement attendu du système.
6. Le champ "weight" reflète l'importance du cas de test et accepte 4 valeurs : "LOW", "MEDIUM", "HIGH" ou "VERY_HIGH".
7. Le champ "reference" est un identifiant court et unique pour le cas de test qui suit le formalisme "TC_AI_<domain>_<number>".
Contraintes de fiabilité (très important) :
- Utilisez uniquement les informations explicitement présentes dans le besoin métier et le contexte fournis.
- Si un test nécessite des informations manquantes, ne les inventez pas.
Écrivez l'hypothèse dans "prerequisites" en commençant par "Hypothèse :".
- Ne référencez pas des éléments d'interface ou des écrans qui ne sont pas mentionnés dans les données d'entrée.
Raisonnement interne (ne pas afficher) :
Avant d'écrire le JSON, effectuez silencieusement :
(1) extraire les règles métier + champs obligatoires + entités clés,
(2) identifier les variables qui changent entre les scénarios (ce sont vos paramètres),
(3) vérifier que chaque paramètre apparaît au moins une fois dans "prerequisites", "action" ou "expectedResult",
(4) générer les jeux de données couvrant nominal, erreurs et cas limites.
Stratégie de variabilisation :
- Si possible, ne générez qu'un seul cas de test bien variabilisé qui couvre tous les scénarios (nominal + erreurs) grâce aux jeux de données.
- Les paramètres s'écrivent ${nomDuParametre} et peuvent être utilisés dans "prerequisites", "action" et "expectedResult", mais pas dans "name" et "description".
- Règle critique : chaque paramètre défini dans les jeux de données doit absolument apparaître au moins une fois dans "prerequisites", "action" ou "expectedResult".
Un paramètre défini mais jamais utilisé est une erreur.
Inversement, un ${parameter} utilisé dans les pas de test mais absent des jeux de données est une erreur.
- Pour les noms de paramètres : uniquement lettres ASCII, chiffres, tirets et underscores.
Pas d'espaces. Maximum 255 caractères.
- Chaque jeu de données représente un scénario de test (nominal, erreur, cas limite).
Le champ "name" du jeu de données décrit le scénario couvert.
Format de sortie (JSON uniquement, rien d'autre) :
{
"testCases": [
{
"name": "Titre explicite du cas de test",
"reference": "TC_AI_<domain>_<number>",
"description": "Objectif du test",
"weight": "HIGH",
"prerequisites": "Prérequis avec ${parametre1}",
"testSteps": [
{
"action": "Action avec ${parametre1}",
"expectedResult": "Résultat attendu : ${parametre2}"
}
],
"datasets": [
{
"name": "Scénario nominal - description claire",
"parameters": {
"parametre1": "valeur1",
"parametre2": "valeur2"
}
},
{
"name": "Cas d'erreur - description claire",
"parameters": {
"parametre1": "valeur_erreur1",
"parametre2": "valeur_erreur2"
}
}
]
}
]
}
La réponse doit être un objet JSON valide et uniquement cela : pas de balises de code, pas de commentaires, pas de formatage markdown.
Tout caractère en dehors du JSON invalide la réponse.
Générez des cas de test variabilisés avec jeux de données pour l'exigence suivante :
Nom : {{requirement.name}}
Référence : {{requirement.reference}}
Criticité : {{requirement.criticality}}
Catégorie : {{requirement.category}}
Nature : {{requirement.nature}}
Description :
{{requirement.description}}
{{ userPrompt }}
{{#if providedRequirements}}
--- EXIGENCES LIÉES (contexte additionnel) ---
{{#each providedRequirements}}
[{{@index}}] {{this.name}} : {{this.description}}
{{/each}}
{{/if}}
{{#if providedDocuments}}
--- DOCUMENTS DE RÉFÉRENCE ---
{{#each providedDocuments}}
- {{this.name}}
{{/each}}
{{/if}}
Supprimer un ensemble de prompts
Il est possible de supprimer un ensemble de prompts depuis sa page de consultation ou directement depuis le tableau de gestion.
Focus
La suppression d'un ensemble de prompts entraîne la suppression de tous les prompts qu'il contient. Si cet ensemble est lié à l'usage IA d'un projet, la fonctionnalité concernée ne fonctionnera plus tant qu'un nouvel ensemble de prompts n'aura pas été associé.
Info
Les ensembles de prompts par défaut (badge "S") sont protégés et ne peuvent pas être supprimés.