Gérer les serveurs d'intelligence artificielle
Info
La génération de cas de test par intelligence artificielle est disponible avec une licence SquashTM Ultimate 💎 et le plugin SquashTM Premium.
Attention
Les serveurs d'IA étaient une fonctionnalité expérimentale ajoutée dans Squash TM 7. Dans SquashTM 13, ces serveurs ont été entièrement repensés. Les serveurs d'IA déclarés dans SquashTM 12 ou antérieur (indiqués comme "legacy") sont toujours utilisables, mais aucun nouveau serveur legacy ne peut être ajouté. Le support des serveurs d'IA legacy sera supprimé dans SquashTM 16.
Ajouter ou supprimer un serveur d'intelligence artificielle

Depuis le tableau Serveurs d'intelligence artificielle, accessible en cliquant sur l'icône 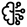 , vous pouvez ajouter
, vous pouvez ajouter  ou supprimer
ou supprimer  un ou plusieurs serveurs.
un ou plusieurs serveurs.
Si vous supprimez un serveur lié à un projet, il sera retiré de la configuration de ce projet.
Lors de la création d'un serveur, les champs Nom, Fournisseur d'API, URL et Modèle doivent être renseignés. L'URL est l'URL de base des endpoints (points de terminaison) d'API du fournisseur.
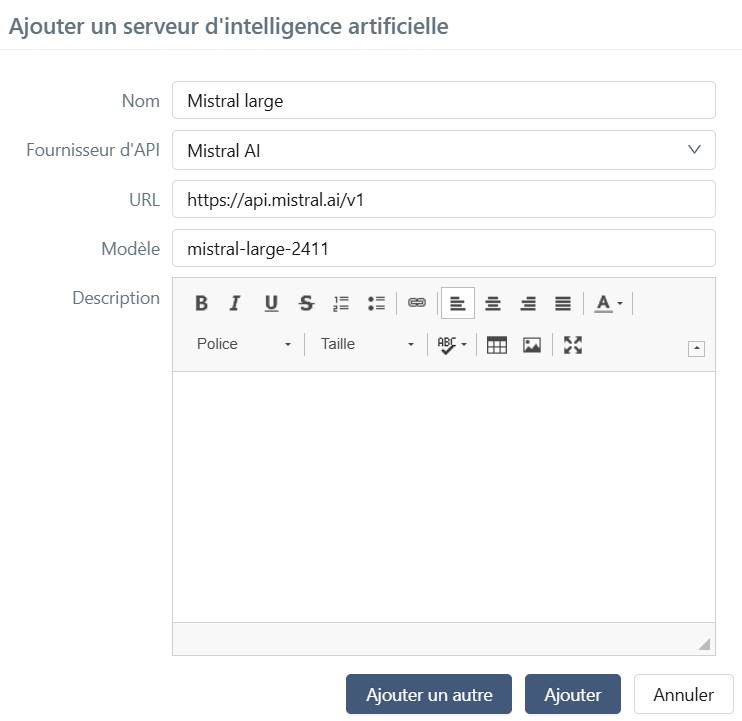
Cliquer sur l'ID (#) ou le Nom d'un serveur ouvre sa page de détails, où vous pouvez le configurer entièrement.
Vous pouvez effectuer plusieurs actions depuis la page de consultation du serveur d'IA :
- définir ou modifier le Nom, le Fournisseur d'API, l'URL, le Modèle et la Description du serveur ;
- définir la Clé d'API d'authentification du serveur ;
- définir les paramètres de configuration spécifiques au fournisseur ;
- tester la configuration ;
- supprimer le serveur d'IA en utilisant le bouton [...].
SquashTM supporte nativement plusieurs fournisseurs d'IA majeurs, avec, de plus, un mécanisme qui permet la configuration de tout autre fournisseur.
Les paragraphes suivants décrivent la configuration pour chaque fournisseur.
Configurer un serveur d'intelligence artificielle
Configuration des paramètres de modèle
Chaque fournisseur d'IA prend en charge des paramètres de configuration différents, leur comportement varie selon le modèle.
Avant de configurer les paramètres :
Consultez la documentation du fournisseur (référencée dans chaque section ci-dessous) pour
- vérifier quels paramètres sont pris en charge par le modèle que vous avez sélectionné ;
- déterminer l'applicabilité d'un paramètre qui peut dépendre de la valeur d'un autre ;
- connaître la valeur par défaut de chaque paramètre lorsqu'il n'est pas spécifié.
Valeurs par défaut :
Si vous ne définissez pas un paramètre, le fournisseur utilise généralement sa propre valeur par défaut. Cependant, dans quelques cas, la bibliothèque d'IA intégrée à SquashTM imposera une valeur spécifique à la place. Lorsque cela se produit, la valeur par défaut imposée est documentée dans la section du fournisseur concerné ci-dessous.
Configuration pour Anthropic
L'URL par défaut est https://api.anthropic.com/v1, c'est l'URL racine pour les endpoints d'API pour accéder aux modèles hébergés par Anthropic eux-mêmes. Si vous utilisez une API Anthropic hébergée ailleurs, vous devez modifier cette URL par défaut.
Les modèles fournis par Anthropic sont listés ici.
La Clé d'API doit être générée depuis votre page de compte Anthropic.
Le paramètre de requête suivant peut être défini :
- Timeout
La durée maximale (en secondes) autorisée pour attendre la réponse du modèle.
Les paramètres de modèle suivants (décrits sur cette page) peuvent être ajustés :
- Temperature
- Top-p
- Max tokens
Si non défini, la valeur par défaut1024est transmise à Anthropic. - Thinking type
- Thinking budget tokens
Configuration pour OpenAI
L'URL par défaut est https://api.openai.com/v1, c'est l'URL racine pour les endpoints d'API pour accéder aux modèles hébergés par OpenAI eux-mêmes. Si vous utilisez une API OpenAI hébergée ailleurs, vous devez modifier cette URL par défaut. Dans le cas d'Azure OpenAI, voir le paragraphe ci-dessous.
Les modèles fournis par OpenAI sont listés ici. Assurez-vous d'utiliser un modèle supportant l'endpoint v1/chat/completions, ce support est indiqué sur la page de description de chaque modèle.
La Clé d'API doit être générée depuis votre page de compte OpenAI.
Les paramètres de requête suivants peuvent être définis :
- Organization ID
- Timeout
La durée maximale (en secondes) autorisée pour attendre la réponse du modèle.
Les paramètres de modèle suivants (décrits sur cette page) peuvent être ajustés :
- Temperature
- Top-p
- Seed
- Max completion tokens
- Reasoning effort
Configuration pour Mistral AI
L'URL par défaut est https://api.mistral.ai/v1, c'est l'URL racine pour les endpoints d'API pour accéder aux modèles hébergés par Mistral AI eux-mêmes. Si vous utilisez une API Mistral AI hébergée ailleurs, vous devez modifier cette URL par défaut.
Les modèles fournis par Mistral AI sont listés ici. Assurez-vous d'utiliser un modèle texte vers texte, vous pouvez vérifier les fonctionnalités de chaque modèle sur cette page.
Info
Seul un sous-ensemble des modèles Mistral est pris en charge. Reportez-vous à la documentation LangChain4j pour connaître la liste actuelle des modèles supportés.
La Clé d'API doit être générée depuis votre page d'organisation Mistral AI.
Le paramètre de requête suivant peut être défini :
- Timeout
La durée maximale (en secondes) autorisée pour attendre la réponse du modèle.
Les paramètres de modèle suivants (décrits sur cette page) peuvent être ajustés :
- Temperature
- Top-p
- Random seed
- Max tokens
Configuration pour Azure OpenAI
L'URL par défaut est https://YOUR_RESOURCE_NAME.openai.azure.com. Vous devez remplacer YOUR_RESOURCE_NAME par le nom de votre ressource Microsoft Azure.
Les modèles fournis par Azure OpenAI sont listés ici.
La Clé d'API doit être générée depuis votre page de ressource sur le Portail Microsoft Azure.
Les paramètres de requête suivants peuvent être définis :
- API version
Les valeurs autorisées sont2022-12-01,2023-05-15,2023-06-01-preview,2023-07-01-preview,2024-02-01,2024-02-15-preview,2024-03-01-preview,2024-04-01-preview,2024-05-01-preview,2024-06-01,2024-07-01-preview,2024-08-01-preview,2024-09-01-preview,2024-10-01-previewou2025-01-01-preview. - Timeout
La durée maximale (en secondes) autorisée pour attendre la réponse du modèle.
Les paramètres de modèle suivants (décrits sur cette page) peuvent être ajustés :
- Temperature
- Top-p
- Seed
- Max tokens
- Max completion tokens
Configuration pour Google Vertex AI
Le champ URL n'est pas utilisé.
Les modèles fournis par Google Vertex AI, ainsi que les régions où chacun est disponible, sont listés ici.
Vous devez générer la clé privée JSON dans votre Console Google Cloud.
Elle doit avoir ce format :
{
"type": "...",
"project_id": "...",
"private_key_id": "...",
"private_key": "...",
"client_email": "...",
"client_id": "...",
"auth_uri": "...",
"token_uri": "...",
"auth_provider_x509_cert_url": "...",
"client_x509_cert_url": "...",
"universe_domain": "..."
}
Les paramètres de requête suivants doivent être définis :
- Project ID
Votre ID de projet Google Cloud. - Region
La région où l'inférence IA doit avoir lieu.
Les paramètres de modèle suivants (décrits sur cette page) peuvent être ajustés :
- Temperature
- Top-p
- Seed
- Max output tokens
Configuration d'un serveur d'IA personnalisé
La configuration d'un serveur d'IA personnalisé est décrite sur cette page.
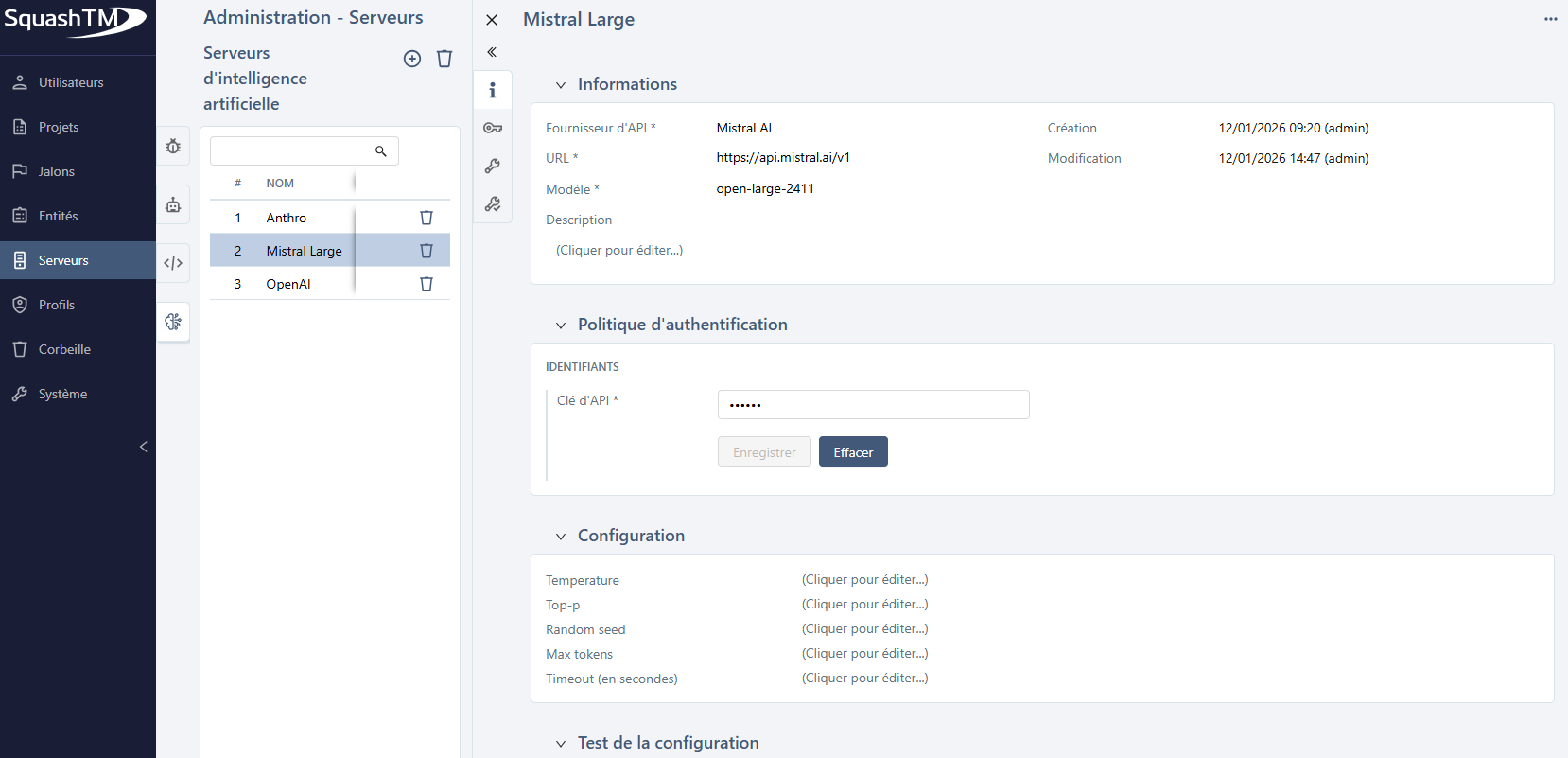
Tester la configuration d'un serveur d'Intelligence Artificielle
Cette fonctionnalité permet de vérifier que le serveur d'IA est correctement configuré.
Vous pouvez modifier ces prompts pour votre test, mais ces changements ne seront pas enregistrés.
Résultat attendu
Si la connexion au serveur d'IA et la génération fonctionnent correctement, la réponse doit être similaire à :
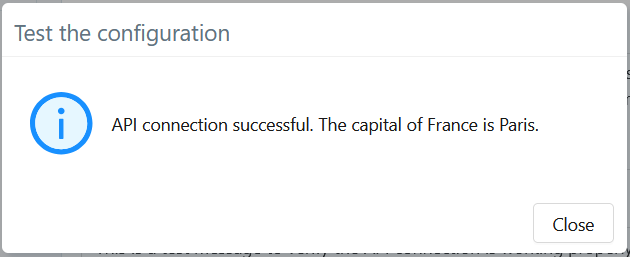
Affichage des erreurs
Si la requête échoue, un message d'erreur s'affiche accompagné de la réponse renvoyée par le fournisseur d'API.
Les erreurs courantes incluent :
- une clé API invalide ou absente ;
- un nom de modèle ou un endpoint incorrect ;
- un délai d'attente dépassé ou un problème réseau ;
- une erreur côté fournisseur.
Le panneau affiche l'erreur brute retournée par l'API afin de faciliter le diagnostic.
Par exemple : 
Indisponibilité pour SquashTM Cloud
Pour des raisons de sécurité, ce message d'erreur n'est pas accessible par les utilisateurs de l'offre SquashTM Cloud qui utilisent une URL autre que celle par défaut du fournisseur d'API.